Published Work
Breaking the Million-Token Barrier: The Technical Achievement of Azure ND GB300 v6
Azure High Performance Computing Blog - Nov 3, 2025
TL;DR: Azure ND GB300 v6 Virtual Machines with NVIDIA GB300 NVL72 rack-scale systems achieve unprecedented performance of 1,100,000 tokens/s on Llama2 70B Inference, beating the previous Azure ND GB200 v6 record of 865,000 tokens/s by 27%. Learn about the Azure AI Infrastructure and how to reproduce the results.
Azure High Performance Computing Blog - Nov 3, 2025
TL;DR: Azure ND GB300 v6 Virtual Machines with NVIDIA GB300 NVL72 rack-scale systems achieve unprecedented performance of 1,100,000 tokens/s on Llama2 70B Inference, beating the previous Azure ND GB200 v6 record of 865,000 tokens/s by 27%. Learn about the Azure AI Infrastructure and how to reproduce the results.

The Business Impact of Azure ND GB300 v6 Performance for Enterprise AI
Signal65 White Paper - Nov 3, 2025
TL;DR: In testing validated by Signal65, Microsoft Azure has demonstrated an aggregate LLM inference throughput of 1,100,948 tokens per second on a single rack of its next-generation ND GB300 v6 virtual machine infrastructure, powered by 72 NVIDIA GB300 GPUs. This milestone is significant not just for breaking the one-million-token-per-second barrier and being an industry-first, but for doing so on a platform architected to meet the dynamic use and data governance needs of modern enterprises.
Signal65 White Paper - Nov 3, 2025
TL;DR: In testing validated by Signal65, Microsoft Azure has demonstrated an aggregate LLM inference throughput of 1,100,948 tokens per second on a single rack of its next-generation ND GB300 v6 virtual machine infrastructure, powered by 72 NVIDIA GB300 GPUs. This milestone is significant not just for breaking the one-million-token-per-second barrier and being an industry-first, but for doing so on a platform architected to meet the dynamic use and data governance needs of modern enterprises.

Inside the world’s most powerful AI datacenter
Official Microsoft Blog - Sep 18, 2025
TL;DR: We introduced Fairwater, our newest US AI datacenter, the largest and most sophisticated AI factory we’ve built yet which delivers 865,000 tokens/s per rack.
Official Microsoft Blog - Sep 18, 2025
TL;DR: We introduced Fairwater, our newest US AI datacenter, the largest and most sophisticated AI factory we’ve built yet which delivers 865,000 tokens/s per rack.

Optimizing Large-Scale AI Performance with Pretraining Validation on a Single Azure ND GB200 v6
Signal65 White Paper - Sep 9, 2025
TL;DR: We focus on the Microsoft Azure ND GB200 v6 virtual machines (VMs) accelerated by the NVIDIA GB200 NVL4. We analyze Azure’s MLPerf results in the Llama2 70B and Llama3.1 405B benchmarks, explain why these tests matter for real deployments, and translate raw data into actionable insights.
Signal65 White Paper - Sep 9, 2025
TL;DR: We focus on the Microsoft Azure ND GB200 v6 virtual machines (VMs) accelerated by the NVIDIA GB200 NVL4. We analyze Azure’s MLPerf results in the Llama2 70B and Llama3.1 405B benchmarks, explain why these tests matter for real deployments, and translate raw data into actionable insights.

Optimizing Large-Scale AI Performance with Pretraining Validation on a Single Azure ND GB200 v6
Azure High Performance Computing Blog - Aug 18, 2025
TL;DR: Single-VM benchmarking with lightweight Llama pretraining on Azure’s ND GB200 v6 VMs helps catch costly performance issues early by tuning parallelism parameters and analyzing telemetry before scaling to multi-node runs.
Azure High Performance Computing Blog - Aug 18, 2025
TL;DR: Single-VM benchmarking with lightweight Llama pretraining on Azure’s ND GB200 v6 VMs helps catch costly performance issues early by tuning parallelism parameters and analyzing telemetry before scaling to multi-node runs.

Performance at Scale: The Role of Interconnects in Azure HPC & AI Infrastructure
Azure High Performance Computing Blog - Jun 25, 2025
TL;DR: Azure’s AI network enables efficient, scalable training for large AI models. Using xAI’s 314B Grok-1, performance scaled linearly from 8 to 1024 GPUs with NeMo, matching NVIDIA’s on-prem results.
Azure High Performance Computing Blog - Jun 25, 2025
TL;DR: Azure’s AI network enables efficient, scalable training for large AI models. Using xAI’s 314B Grok-1, performance scaled linearly from 8 to 1024 GPUs with NeMo, matching NVIDIA’s on-prem results.

DGX Cloud Benchmarking on Azure
Azure High Performance Computing Blog - May 5, 2025
TL;DR: Azure’s ND H100 v5 platform and its highly optimized software stack deliver world-class LLM training performance. Here are the optimal NCCL parameters and NeMo configuration that enabled parity in throughput and scaling efficiency with NVIDIA DGX Cloud.
Azure High Performance Computing Blog - May 5, 2025
TL;DR: Azure’s ND H100 v5 platform and its highly optimized software stack deliver world-class LLM training performance. Here are the optimal NCCL parameters and NeMo configuration that enabled parity in throughput and scaling efficiency with NVIDIA DGX Cloud.

Azure’s ND GB200 v6 Delivers Record Performance for Inference Workloads
Azure High Performance Computing Blog - Mar 31, 2025
TL;DR: Azure’s ND GB200 v6 VMs, powered by NVIDIA GB200 NVL72, set a new inference world record with 865,000 tokens/sec on LLAMA 2 70B—delivering 3.9× GPU-level and 9× rack-level throughput gains over ND H100 v5 for enterprise-scale AI workloads.
Azure High Performance Computing Blog - Mar 31, 2025
TL;DR: Azure’s ND GB200 v6 VMs, powered by NVIDIA GB200 NVL72, set a new inference world record with 865,000 tokens/sec on LLAMA 2 70B—delivering 3.9× GPU-level and 9× rack-level throughput gains over ND H100 v5 for enterprise-scale AI workloads.

Leading AI Scalability Benchmarks with Microsoft Azure
Signal65 White Paper - Nov 13, 2024
TL;DR: Azure leads in cloud-based AI scalability and efficiency, outperforming a top competitor by 28% in LLaMA 70B fine-tuning with identical GPU counts. MLPerf 4.1 benchmarks confirm Azure’s leadership in performance, scale, and price/performance for enterprise AI workloads.
Signal65 White Paper - Nov 13, 2024
TL;DR: Azure leads in cloud-based AI scalability and efficiency, outperforming a top competitor by 28% in LLaMA 70B fine-tuning with identical GPU counts. MLPerf 4.1 benchmarks confirm Azure’s leadership in performance, scale, and price/performance for enterprise AI workloads.

Optimizing Language Model Inference on Azure
Azure High Performance Computing Blog - Oct 2, 2024
TL;DR: Azure’s ND H200 v5 VMs boost inference efficiency with 76% more GPU memory. Enabling optimized batch sizes that maximize throughput while balancing latency, customers can reduce costs by 20% through data-driven resource tuning.
Azure High Performance Computing Blog - Oct 2, 2024
TL;DR: Azure’s ND H200 v5 VMs boost inference efficiency with 76% more GPU memory. Enabling optimized batch sizes that maximize throughput while balancing latency, customers can reduce costs by 20% through data-driven resource tuning.

Microsoft Azure delivers game-changing performance for generative AI Inference
Microsoft Azure - Mar 27, 2024
TL;DR: Azure’s investments in the 94GB HBM3 memory version of the NVIDIA H100 NVL GPUs deliver up to 46% better inference throughput than competitors. The represents a 1.6× speedup over prior Azure generations—enabling efficient handling of mega-models inference with unmatched memory and scalability in the cloud.
Microsoft Azure - Mar 27, 2024
TL;DR: Azure’s investments in the 94GB HBM3 memory version of the NVIDIA H100 NVL GPUs deliver up to 46% better inference throughput than competitors. The represents a 1.6× speedup over prior Azure generations—enabling efficient handling of mega-models inference with unmatched memory and scalability in the cloud.

A quick start guide to benchmarking AI models in Azure: Llama 2 from MLPerf Inference v4.0
Azure High Performance Computing Blog - Mar 27, 2024
TL;DR: Reproduce the MLPerf Inference v4.0 results in less than 1 hour on the new NC H100 v5 VMs.
Azure High Performance Computing Blog - Mar 27, 2024
TL;DR: Reproduce the MLPerf Inference v4.0 results in less than 1 hour on the new NC H100 v5 VMs.
Azure sets a scale record in large language model training
Microsoft Azure - Nov 8, 2023
TL;DR: Azure set a new record by training GPT-3 (175B parameters) in 4 minutes on 10,752 NVIDIA H100 GPUs—achieving within 2% of bare-metal performance—showcasing its unmatched scale, efficiency, and virtualization in powering state-of-the-art LLM training and inference workloads.
Microsoft Azure - Nov 8, 2023
TL;DR: Azure set a new record by training GPT-3 (175B parameters) in 4 minutes on 10,752 NVIDIA H100 GPUs—achieving within 2% of bare-metal performance—showcasing its unmatched scale, efficiency, and virtualization in powering state-of-the-art LLM training and inference workloads.
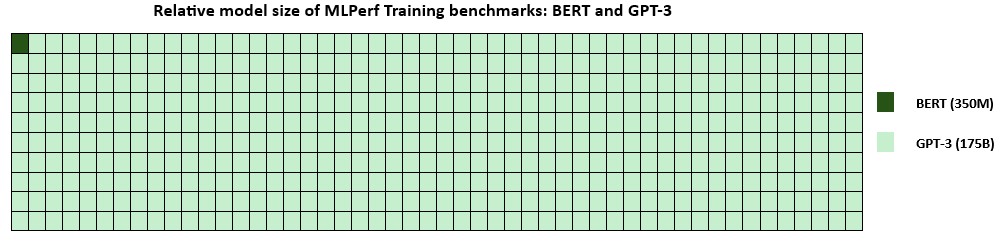
A Quick Guide to Benchmarking AI Models on Azure: ResNet with MLPerf Training v3.0
Azure High Performance Computing Blog - Jun 28, 2023
TL;DR: Reproduce the MLPerf Training v3.0 results in less than 1 hour on the new ND H100 v5 VMs.
Azure High Performance Computing Blog - Jun 28, 2023
TL;DR: Reproduce the MLPerf Training v3.0 results in less than 1 hour on the new ND H100 v5 VMs.
Tackling AI Inference workloads on Azure’s NC A100 v4 virtual machines with time to spare
Azure High Performance Computing Blog - Jan 26, 2023
TL;DR: Azure NC A100 v4-series VMs offer flexible, scalable AI compute with NVIDIA MIG technology and deliver up to 2.9x better cost efficiency than T4-based VMs: ideal for diverse workloads from small to mid-size AI inference and training.
Azure High Performance Computing Blog - Jan 26, 2023
TL;DR: Azure NC A100 v4-series VMs offer flexible, scalable AI compute with NVIDIA MIG technology and deliver up to 2.9x better cost efficiency than T4-based VMs: ideal for diverse workloads from small to mid-size AI inference and training.
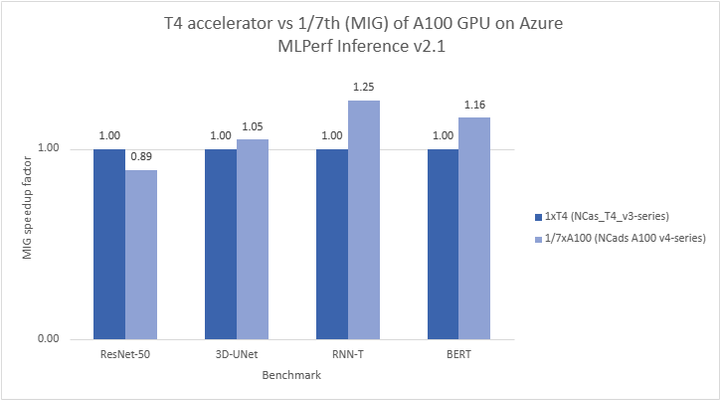
A quick start guide to benchmarking AI models in Azure: MLPerf Inference v2.1 on Multi-Instance GPU
Azure High Performance Computing Blog - Jan 26, 2023
TL;DR: Reproduce the MLPerf Inference v2.1 on up to 7 MIG partitions with the new NC A100 v4 VMs.
Azure High Performance Computing Blog - Jan 26, 2023
TL;DR: Reproduce the MLPerf Inference v2.1 on up to 7 MIG partitions with the new NC A100 v4 VMs.

Large language models broaden AI’s reach in industry and enterprises
VentureBeat Press Article - Dec 15, 2022
TL;DR: LLMs like ChatGPT are transforming AI across industries by enabling powerful language tasks. Their growth demands scalable, efficient infrastructure, made possible by Microsoft and NVIDIA leading cloud.
VentureBeat Press Article - Dec 15, 2022
TL;DR: LLMs like ChatGPT are transforming AI across industries by enabling powerful language tasks. Their growth demands scalable, efficient infrastructure, made possible by Microsoft and NVIDIA leading cloud.

Azure Collaborates with Hazy Research and NVIDIA to Achieve Unmatched MLPerf Results
Azure High Performance Computing Blog - Nov 9, 2022
TL;DR: Azure worked with Hazy Research’s FlashAttention software optimization to become the only submitter to train BERT in under 2 minutes on 16 VMs, demonstrating efficient, scalable AI training in the cloud that outperforms on-premises setups.
Azure High Performance Computing Blog - Nov 9, 2022
TL;DR: Azure worked with Hazy Research’s FlashAttention software optimization to become the only submitter to train BERT in under 2 minutes on 16 VMs, demonstrating efficient, scalable AI training in the cloud that outperforms on-premises setups.

HPC Wire - Azure Collaborates with Hazy Research and NVIDIA to Achieve Unmatched MLPerf Results
HPC Wire Press Article - Nov 9, 2022
TL;DR: Learn about Hazy Research’s FlashAttention software optimization developed on Azure.
HPC Wire Press Article - Nov 9, 2022
TL;DR: Learn about Hazy Research’s FlashAttention software optimization developed on Azure.

A Quick Guide to Benchmarking AI models on Azure: Mask R-CNN with MLPerf Training v2.1
Azure High Performance Computing Blog - Nov 9, 2022
TL;DR: Reproduce the MLPerf Training v2.1 results in less than 1 hour on the new NDm A100 v4 VMs.
Azure High Performance Computing Blog - Nov 9, 2022
TL;DR: Reproduce the MLPerf Training v2.1 results in less than 1 hour on the new NDm A100 v4 VMs.
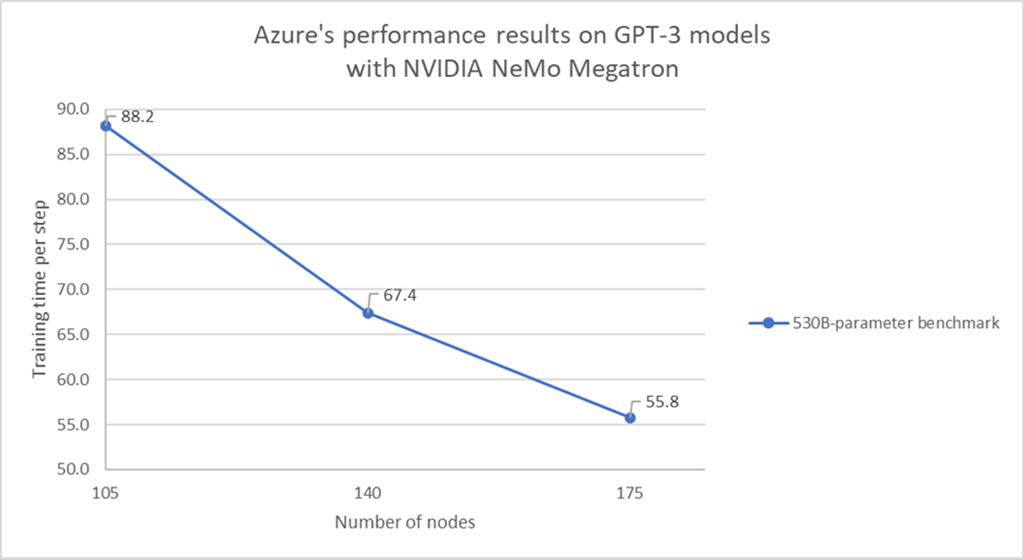
Azure Scales 530B Parameter GPT-3 Model with NVIDIA NeMo Megatron
HPC Wire Press Article - Oct 24, 2022
TL;DR: Training a 530-billion-parameter LLM in the cloud on Azure’s NDm A100 v4 VMs set a groundbreaking proof of concept for enabling and accelerating training AI models at massive scale.
HPC Wire Press Article - Oct 24, 2022
TL;DR: Training a 530-billion-parameter LLM in the cloud on Azure’s NDm A100 v4 VMs set a groundbreaking proof of concept for enabling and accelerating training AI models at massive scale.

A quick start guide to benchmarking LLM models in Azure: NVIDIA NeMo Megatron - Results
Azure High Performance Computing Blog - Oct 24, 2022
TL;DR: Azure NDm A100 v4 VMs combined with NVIDIA NeMo Megatron demonstrated near-linear scaling and optimized training speeds for LLMs from 126 million to 530 billion parameters by efficiently balancing tensor and pipeline model parallelism.
Azure High Performance Computing Blog - Oct 24, 2022
TL;DR: Azure NDm A100 v4 VMs combined with NVIDIA NeMo Megatron demonstrated near-linear scaling and optimized training speeds for LLMs from 126 million to 530 billion parameters by efficiently balancing tensor and pipeline model parallelism.
A quick start guide to benchmarking LLM models in Azure: NVIDIA NeMo Megatron - Steps
Azure High Performance Computing Blog - Oct 24, 2022
TL;DR: Reproduce the GPT-3 Model training for 126M to 530B parameters.
Azure High Performance Computing Blog - Oct 24, 2022
TL;DR: Reproduce the GPT-3 Model training for 126M to 530B parameters.
A quick start guide to benchmarking AI models in Azure: MLPerf Inference v2.1
Azure High Performance Computing Blog - Sep 8, 2022
TL;DR: Reproduce the MLPerf Inference v2.1 results in less than 1 hour on the new NV A10 v5 VMs.
Azure High Performance Computing Blog - Sep 8, 2022
TL;DR: Reproduce the MLPerf Inference v2.1 results in less than 1 hour on the new NV A10 v5 VMs.
Maximizing AI performance with the Azure NC A100 v4-series
Azure High Performance Computing Blog - Aug 10, 2022
TL;DR: Azure’s new NC A100 v4-series VMs deliver industry-leading AI training and inference performance that rivals on-premises systems, offering up to 5x faster results and 2-3x better cost efficiency for diverse small-to-medium AI workloads.
Azure High Performance Computing Blog - Aug 10, 2022
TL;DR: Azure’s new NC A100 v4-series VMs deliver industry-leading AI training and inference performance that rivals on-premises systems, offering up to 5x faster results and 2-3x better cost efficiency for diverse small-to-medium AI workloads.
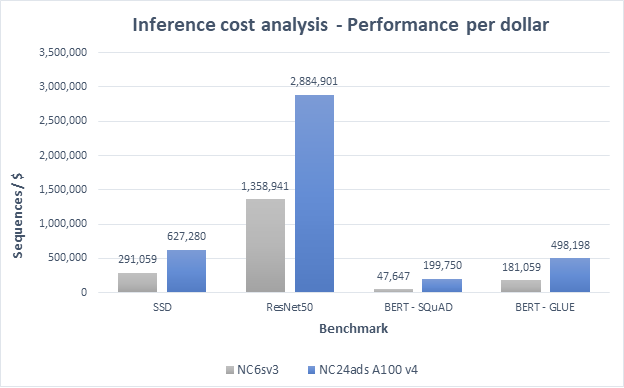
A quick start guide to benchmarking AI models in Azure: MLPerf Training v2.0
Azure High Performance Computing Blog - Aug 3, 2022
TL;DR: Reproduce the MLPerf Training v2.0 results in less than 1 hour on the new ND A100 v4 VMs.
Azure High Performance Computing Blog - Aug 3, 2022
TL;DR: Reproduce the MLPerf Training v2.0 results in less than 1 hour on the new ND A100 v4 VMs.
Getting started with Multi-Instance GPU (MIG) on the NC A100 v4-series
Azure High Performance Computing Blog - Aug 3, 2022
TL;DR: How to deploy MIG instances on the NC A100 v4 VMs in 10 min.
Azure High Performance Computing Blog - Aug 3, 2022
TL;DR: How to deploy MIG instances on the NC A100 v4 VMs in 10 min.
Getting started with the NC A100 v4-series
Azure High Performance Computing Blog - Jul 8, 2022
TL;DR: How to set up a NC A100 v4 VM in less than 4 min.
Azure High Performance Computing Blog - Jul 8, 2022
TL;DR: How to set up a NC A100 v4 VM in less than 4 min.
Benchmarking the NC A100 v4, NCsv3, and NCas_T4_v3 series with NVIDIA Deep Learning Examples
Azure High Performance Computing Blog - Jul 8, 2022
TL;DR: Reproduce the NVIDIA Deep Learning Examples benchmarks on all AI virtual machines on Azure.
Azure High Performance Computing Blog - Jul 8, 2022
TL;DR: Reproduce the NVIDIA Deep Learning Examples benchmarks on all AI virtual machines on Azure.
Getting started with the NCsv3 series and NCas_T4_v3 series
Azure High Performance Computing Blog - Jul 8, 2022
TL;DR: How to set up a NC V100 v3 VM or a NC T4 v3 VM in less than 5 min.
Azure High Performance Computing Blog - Jul 8, 2022
TL;DR: How to set up a NC V100 v3 VM or a NC T4 v3 VM in less than 5 min.
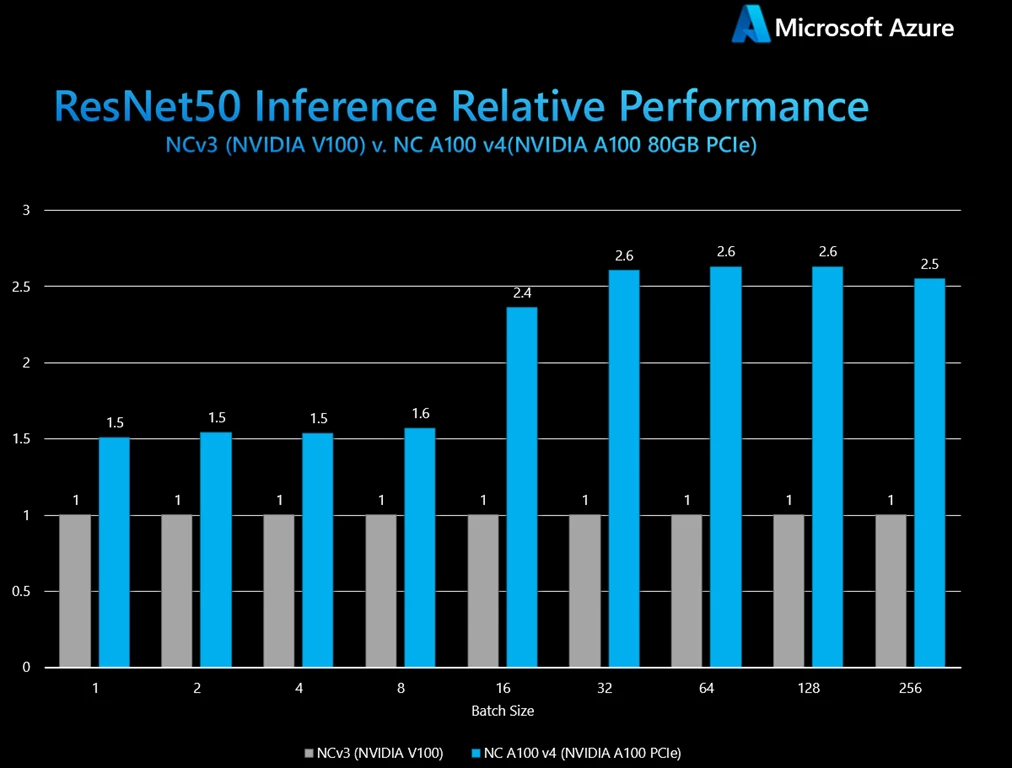
A quick start to benchmarking in Azure: NVIDIA Deep Learning Examples on the NC-series
Azure High Performance Computing Blog - Jul 6, 2022
TL;DR: Azure’s NC A100 v4-series VMs powered by NVIDIA A100 GPUs deliver significantly higher training and inference throughput across BERT, SSD, and ResNet-50 benchmarks—up to 9x faster than NC T4 and 4x faster than NC V100 series—especially at larger batch sizes, showcasing superior performance and scalability for AI workloads.
Azure High Performance Computing Blog - Jul 6, 2022
TL;DR: Azure’s NC A100 v4-series VMs powered by NVIDIA A100 GPUs deliver significantly higher training and inference throughput across BERT, SSD, and ResNet-50 benchmarks—up to 9x faster than NC T4 and 4x faster than NC V100 series—especially at larger batch sizes, showcasing superior performance and scalability for AI workloads.
A quick start guide to benchmarking AI models in Azure: MLPerf Inferencing v2.0
Azure High Performance Computing Blog - Apr 6, 2022
TL;DR: Reproduce the MLPerf Inference v2.0 results in less than 1 hour on the ND and NC A100 v4 VMs.
Azure High Performance Computing Blog - Apr 6, 2022
TL;DR: Reproduce the MLPerf Inference v2.0 results in less than 1 hour on the ND and NC A100 v4 VMs.
Azure AI Supercomputer Delivers Record MLPerf Results
Azure High Performance Computing Blog - Dec 1, 2021
TL;DR: Azure’s debut in MLPerf 1.1 set a new standard for cloud-based AI, ranking #1 among cloud providers and #2 overall, with record-setting performance across BERT, ResNet-50, and Minigo benchmarks using over 2,000 NDm A100 v4 GPUs.
Azure High Performance Computing Blog - Dec 1, 2021
TL;DR: Azure’s debut in MLPerf 1.1 set a new standard for cloud-based AI, ranking #1 among cloud providers and #2 overall, with record-setting performance across BERT, ResNet-50, and Minigo benchmarks using over 2,000 NDm A100 v4 GPUs.